Elastic is open source distributed search engine, based on lucene framework with Rest API. You can download the elastic search using the URLhttp://www.elasticsearch.org/overview/elkdownloads/. Unzip the downloaded zip or tar file and then start one instance or node of elastic search by running the script ‘elasticsearch-1.2.1/bin/elasticsearch’ as shown below:

{kind=link}
Installing plugin:
We can install plugins for enhance feature like elasticsearch-head provide the web interface to interact with its cluster. Use the command ‘elasticsearch-1.2.1/bin/plugin -install mobz/elasticsearch-head’ as shown below:
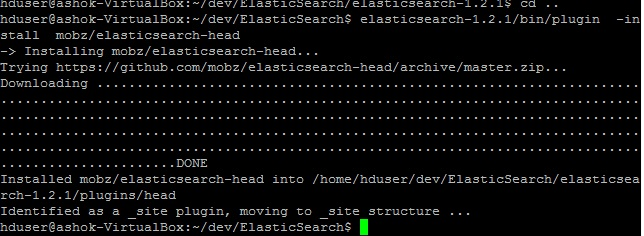
And, Elastic Search web interface can be using url: http://localhost:9200/_plugin/head/
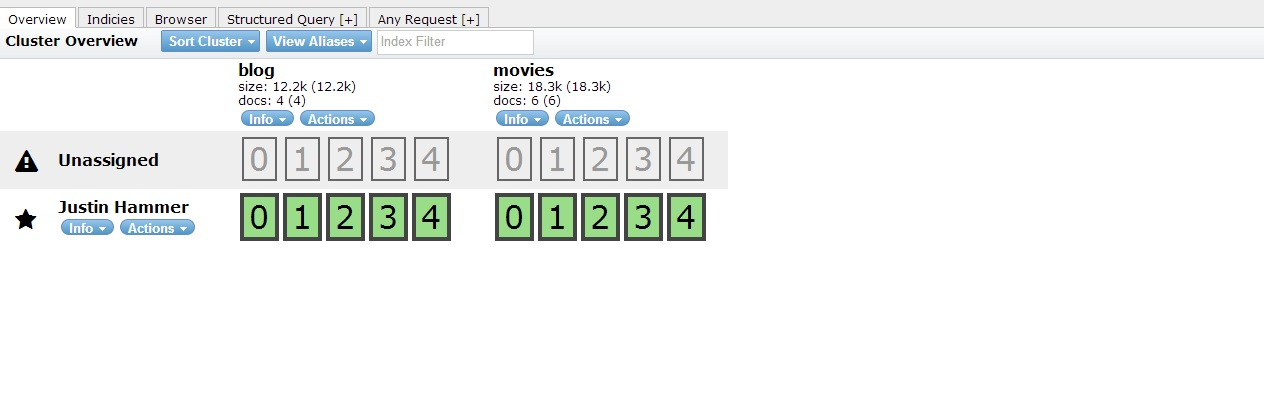
Creating the index:
(You can skip this step) In Search domain, index is like relational database. By default number of shared created is ‘5’ and replication factor “1” which can be changed on creation depending on your requirement. We can increase the number of replication factor but not number of shards.
1
| curl -XPUT "http://localhost:9200/movies/" -d '{"settings" : {"number_of_shards" : 2, "number_of_replicas" : 1}}' |

Create Elastic Search Index
Loading data to Elastic Search:
If we put data to the search domain it will automatically create the index.
Load data using -XPUT
We need to specify the id (1) as shown below:
1
| curl -XPUT "http://localhost:9200/movies/movie/1" -d '{"title": "Men with Wings", "director": "William A. Wellman", "year": 1938, "genres": ["Adventure", "Drama","Drama"]}' |
Note: movies->index, movie->index type, 1->id

Elastic Search -XPUT
Load data using -XPOST
The id will be automatically generated as shown below:
1
| curl -XPOST "http://localhost:9200/movies/movie" -d' { "title": "Lawrence of Arabia", "director": "David Lean", "year": 1962, "genres": ["Adventure", "Biography", "Drama"] }' |

Elastic Search -XPOST
Note: _id: U2oQjN5LRQCW8PWBF9vipA is automatically generated.
The _search endpoint
The index document can be searched using below query:
1
| curl -XPOST "http://localhost:9200/_search" -d' { "query": { "query_string": { "query": "men", "fields": ["title"] } } }' |

ES Search Result
Integrating with Map Reduce (Hadoop 1.2.1)
To integrate Elastic Search with Map Reduce follow the below steps:
Add a dependency to pom.xml:
1
2
3
4
5
6
7
8
9
| <dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch-hadoop</artifactId><version>2.0.0</version></dependency> |
or Download and add elasticSearch-hadoop.jar file to classpath.
Elastic Search as source & HDFS as sink:
In Map Reduce job, you specify the index/index type of search engine from where you need to fetch data in hdfs file system. And input format type as ‘EsInputFormat’ (This format type is defined in elasticsearch-hadoop jar). In org.apache.hadoop.conf.Configuration set elastic search index type using field ‘es.resource’ and any search query using field ‘es.query’ and also set InputFormatClass as ‘EsInputFormat’ as shown below:
ElasticSourceHadoopSinkJob.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.MapWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import org.elasticsearch.hadoop.mr.EsInputFormat;public class ElasticSourceHadoopSinkJob { public static void main(String arg[]) throws IOException, ClassNotFoundException, InterruptedException{ Configuration conf = new Configuration(); conf.set("es.resource", "movies/movie"); //conf.set("es.query", "?q=kill"); final Job job = new Job(conf, "Get information from elasticSearch."); job.setJarByClass(ElasticSourceHadoopSinkJob.class); job.setMapperClass(ElasticSourceHadoopSinkMapper.class); job.setInputFormatClass(EsInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); job.setNumReduceTasks(0); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(MapWritable.class); FileOutputFormat.setOutputPath(job, new Path(arg[0])); System.exit(job.waitForCompletion(true) ? 0 : 1); }} |
ElasticSourceHadoopSinkMapper.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import java.io.IOException;import org.apache.hadoop.io.MapWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class ElasticSourceHadoopSinkMapper extends Mapper<Object, MapWritable, Text, MapWritable> { @Override protected void map(Object key, MapWritable value, Context context) throws IOException, InterruptedException { context.write(new Text(key.toString()), value); }} |
HDFS as source & Elastic Search as sink:
In Map Reduce job, specify the index/index type of search engine from where you need to load data from hdfs file system. And input format type as ‘EsOutputFormat’ (This format type is defined in elasticsearch-hadoop jar). ElasticSinkHadoopSourceJob.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.MapWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.elasticsearch.hadoop.mr.EsOutputFormat;public class ElasticSinkHadoopSourceJob {public static void main(String str[]) throws IOException, ClassNotFoundException, InterruptedException{ Configuration conf = new Configuration(); conf.set("es.resource", "movies/movie"); final Job job = new Job(conf, "Get information from elasticSearch."); job.setJarByClass(ElasticSinkHadoopSourceJob.class); job.setMapperClass(ElasticSinkHadoopSourceMapper.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(EsOutputFormat.class); job.setNumReduceTasks(0); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(MapWritable.class); FileInputFormat.setInputPaths(job, new Path("data/ElasticSearchData")); System.exit(job.waitForCompletion(true) ? 0 : 1); }} |
ElasticSinkHadoopSourceMapper.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import java.io.IOException;import org.apache.hadoop.io.ArrayWritable;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.MapWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class ElasticSinkHadoopSourceMapper extends Mapper<LongWritable, Text, NullWritable, MapWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] splitValue=value.toString().split(","); MapWritable doc = new MapWritable(); doc.put(new Text("year"), new IntWritable(Integer.parseInt(splitValue[0]))); doc.put(new Text("title"), new Text(splitValue[1])); doc.put(new Text("director"), new Text(splitValue[2])); String genres=splitValue[3]; if(genres!=null){ String[] splitGenres=genres.split("\\$"); ArrayWritable genresList=new ArrayWritable(splitGenres); doc.put(new Text("genres"), genresList); } context.write(NullWritable.get(), doc); }} |
Integrate with Hive:
Download elasticsearch-hadoop.jar file and include it in path using hive.aux.jars.path as shown below: bin/hive –hiveconf hive.aux.jars.path=<path-of-jar>/elasticsearch-hadoop-2.0.0.jar or ADD elasticsearch-hadoop-2.0.0.jar to <hive-home>/lib and <hadoop-home>/lib
Elastic Search as source & Hive as sink:
Now, create external table to load data from Elastic search as shown below:
1
| CREATE EXTERNAL TABLE movie (id BIGINT, title STRING, director STRING, year BIGINT, genres ARRAY<STRING>) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'movies/movie'); |
You need to specify the elastic search index type using ‘es.resource’ and can specify query using ‘es.query’.

Load data from Elastic Search to Hive
Elastic Search as sink & Hive as source:
Create an internal table in hive like ‘movie_internal’ and load data to it. Then load data from internal table to elastic search as shown below:
- Create internal table:
1
| CREATE TABLE movie_internal (title STRING, id BIGINT, director STRING, year BIGINT, genres ARRAY<STRING>) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '$' MAP KEYS TERMINATED BY '#' LINES TERMINATED BY '\n' STORED AS TEXTFILE; |
- Load data to internal table:
1
| LOAD DATA LOCAL INPATH '<path>/hiveElastic.txt' OVERWRITE INTO TABLE movie_internal; |
hiveElastic.txt
1
2
| Title1,1,dire1,2003,Action$Crime$ThrillerTitle2,2,dire2,2007,Biography$Crime$Drama |
- Load data from hive internal table to ElasticSearch :
1
| INSERT OVERWRITE TABLE movie SELECT NULL, m.title, m.director, m.year, m.genres FROM movie_internal m; |
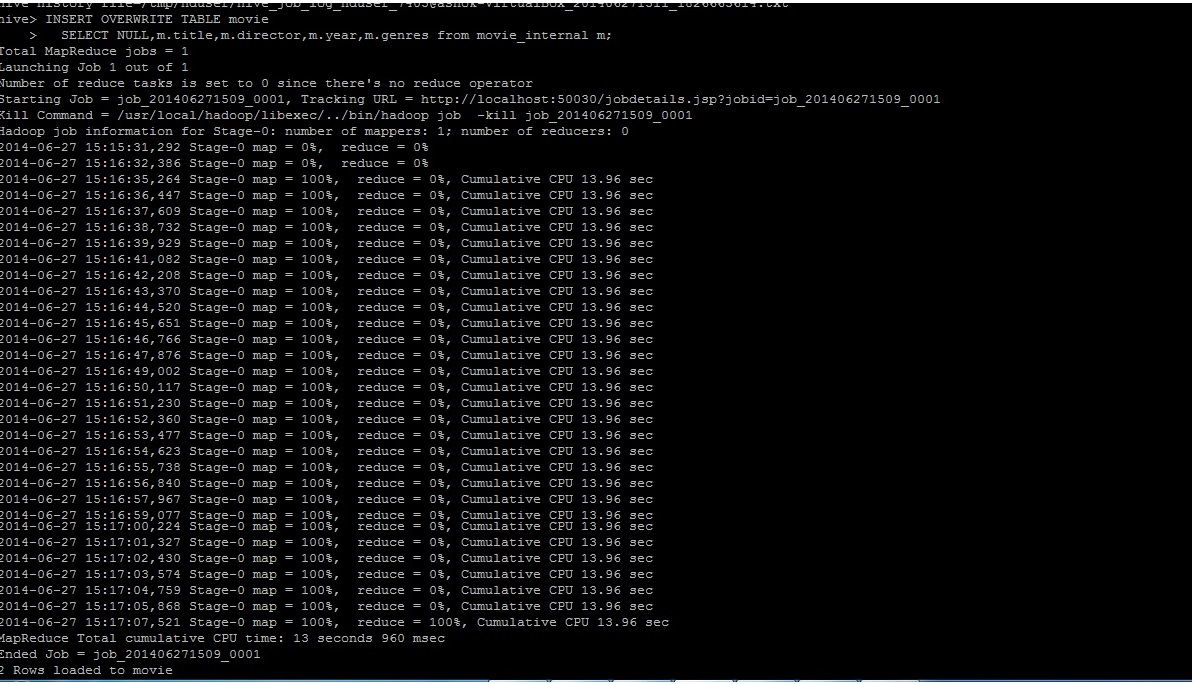
Load data from Hive to Elastic Search

Verify inserted data from Elastic Search query
No comments:
Post a Comment