(If you still think this post is about making windows load faster, then press ALT+F4 to continue)
 |
| Our dear Mr. Client |
Its a fine sunny sunday morning. Due tomorrow, is your presentation to a
client on improving disk-I/O. You pull yourself up by your boots and
manage to climb out of bed and onto your favorite chair...
 |
| I think you forgot to wear your glasses... |
Aahh thats better... You jump into the couch and turn on your laptop and launch
(your favorite presentation app here). As you sip your morning coffee and wait for the app to load, you look out of the window and wonder what it could be doing.
 |
| Looks simple, right? Then why is it taking so long? |
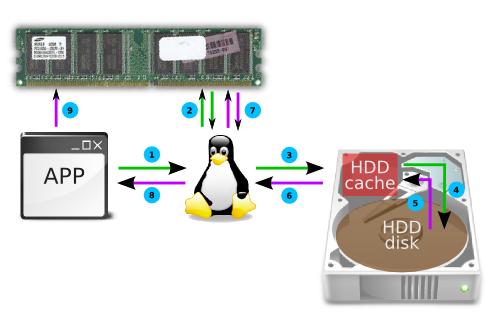
If you would be so kind enough to wipe your rose-coloured glasses clean, you would see that this is what is ACTUALLY happening
0. The app (running in RAM) decides that it wants to play spin-the-wheel with your hard-disk.
1. It initiates a disk-I/O request to read some data from the HDD to RAM(userspace).
2. The kernel does a quick check in its page-cache(again in RAM) to see
if it has this data from any earlier request. Since you just switched-on
your computer,...
3. ...the kernel did NOT find the requested data in the page-cache.
"Sigh!" it says and starts its bike and begins it journey all the way to
HDD-land. On its way, the kernel decides to call-up its old friend
"HDD-cache" and tells him that he will be arriving shortly to collect a
package of data from HDD-land. HDD-cache, the good-friend as always,
tells the kernel not to worry and that everything will be ready by the
time he arrives in HDD-land.
4. HDD-cache starts spinning the HDD-disk...
5. ...and locates and collects the data.
6. The kernel reaches HDD-land and picks-up the data package and starts back.
7. Once back home, it saves a copy of the package in its cache in case
the app asks for it again. (Poor kernel has NO way of knowing that the
app has no such plans).
8. The kernel gives the package of data to the app...
9. ...which promptly stores it in RAM(userspace).
Do keep in mind that this is how it works in case of extremely
disciplined, well-behaved apps. At this point misbehaving apps tend to
go -
"Yo kernel, ACTUALLY, i didn't allocate any RAM, i wanted to just see if
the file existed. Now that i know it does, can you please send me this
other file from some other corner of HDD-land."
...and the story continues...
Time to go refill your coffee-cup. Go go go...
 |
| Hmmm... you are back with some donuts too. Nice caching! |
So as you sit there having coffee and donuts, you wonder how does one
really improve the disk-I/O performance. Improving performance can mean
different things to different people:
- Apps should NOT slow down waiting for data from disk.
- One disk-I/O-heavy app should NOT slow down another app's disk-I/O.
- Heavy disk-I/O should NOT cause increased cpu-usage.
- (Enter your client's requirement here)
So when the disk-I/O throughput is PATHETIC, what does one do?...
 |
| 5 WAYS to optimise your HDD throughput! |
1. Bypass page-cache for "read-once" data.
What exactly does page-cache do? It caches recently accessed pages from
the HDD. Thus reducing seek-times for subsequent accesses to the same
data. The key here being subsequent. The page-cache does NOT improve the
performance the first time a page is accessed from the HDD. So if an
app is going to read a file once and just once, then bypassing the
page-cache is the better way to go. This is possible by using the O_DIRECT
flag. This means that the kernel does NOT considered this particular
data for the page-cache. Reducing cache-contention means that other
pages (which wouold be accessed repeatedly) have a better chance of
being retained in the page-cache. This improves the cache-hit ratio i.e
better performance.
void ioReadOnceFile()
{
/* Using direct_fd and direct_f bypasses kernel page-cache.
* - direct_fd is a low-level file descriptor
* - direct_f is a filestream similar to one returned by fopen()
* NOTE: Use getpagesize() for determining optimal sized buffers.
*/
int direct_fd = open("filename", O_DIRECT | O_RDWR);
FILE *direct_f = fdopen(direct_fd, "w+");
/* direct disk-I/O done HERE*/
fclose(f);
close(fd);
}
2. Bypass page-cache for large files.
Consider the case of a reading in a large file (ex: a database) made of a
huge number of pages. Every subsequent page accessed get into the
page-cache only to be dropped out later as more and more pages are read.
This severely reduces the cache-hit ratio. In this case the page-cache
does NOT provide any performance gains. Hence one would be better off
bypassing the page-cache when accessing large files.
void ioLargeFile()
{
/* Using direct_fd and direct_f bypasses kernel page-cache.
* - direct_fd is a low-level file descriptor
* - direct_f is a filestream similar to one returned by fopen()
* NOTE: Use getpagesize() for determining optimal sized buffers.
*/
int direct_fd = open("largefile.bin", O_DIRECT | O_RDWR | O_LARGEFILE);
FILE *direct_f = fdopen(direct_fd, "w+");
/* direct disk-I/O done HERE*/
fclose(f);
close(fd);
}
3. If (cpu-bound) then scheduler == no-op;
The io-scheduler optimises the order of I/O operations to be queued on
to the HDD. As seek-time is the heaviest penalty on a HDD, most I/O
schedulers attempt to minimise the seek-time. This is implemented as a
variant of the elevator algorithm i.e. re-ordering the randomly ordered
requests from numerous processes to the order in which the data is
present on the HDD. require a significant amount of CPU-time.
Certain tasks that involve complex operations tend to be limited by how
fast the cpu can process vast amounts of data. A complex I/O-scheduler
running in the background can be consuming precious CPU cycles, thereby
reducing the system performance. In this case, switching to a simpler
algorithm like no-op reduces the CPU load and can improve system
performance.
echo noop > /sys/block/<block-dev>/queue/scheduler
4. Block-size: Bigger is Better
Q. How will you move Mount Fuji to bangalore?
to bangalore?
Ans. Bit by bit.
While this will eventually get the job done, its definitely NOT the most
optimal way. From the kernel's perspective, the most optimal size for
I/O requests is the the filesystem blocksize (i.e the page-size). As all
I/O in the filesystem (and the kernel page-cache) is in terms of pages,
it makes sense for the app to do transfers in multiples of pages-size
too. Also with multi-segmented caches making their way into HDDs now,
one would hugely benefit by doing I/O in multiples of block-size.
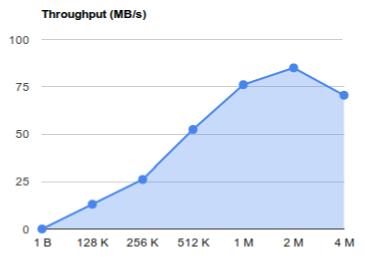 |
| Barracuda 1TB HDD : Optimal I/O block size 2M (=4blocks) |
The following command can be used to determine the optimal block-size
stat --printf="bs=%s optimal-bs=%S\n" --file-system /dev/<block-dev>
5. SYNC vs. ASYNC (& read vs. write)
 |
| ASYNC I/O i.e. non-blocking mode is effectively faster with cache |
When an app initiates a SYNC I/O read,
the kernel queues a read operation for the data and returns only after
the entire block of requested data is read back. During this period, the
Kernel will mark the app's process as blocked for I/O. Other processes
can utilise the CPU, resulting in a overall better performance for the
system.
When an app initiates a SYNC I/O write,
the kernel queues a write operation for the data puts the app's process
in a blocked I/O. Unfortunately what this means is that the current
app's process is blocked and cannot do any other processing (or I/O for
that matter) until this write operation completes.
When an app initiates an ASYNC I/O read,
the read() function usually returns after reading a subset of the large
block of data. The app needs to repeatedly call read() with the size of
data remaining to be read, until the entire required data is read-in.
Each additional call to read introduces some overhead as it introduces a
context-switch between the userspace and the kernel. Implementing a
tight loop to repeatedly call read() wastes CPU cycles that other
processes could have used. Hence one usually implements blocking using
select() until the next read() returns non-zero bytes read-in. i.e the
ASYNC is made to block just like the SYNC read does.
When an app initiates an ASYNC I/O write,
the kernel updates the corresponding pages in the page-cache and marks
them dirty. Then the control quickly returns to the app which can
continue to run. The data is flushed to HDD later at a more optimal time(low cpu-load) in a more optimal way(sequentially bunched writes).
Hence, SYNC-reads and ASYNC-writes are generally a good way to go as they allow the kernel to optimise the order and timing of the underlying I/O requests.
There you go. I bet you now have quite a lot of things to say in your presentation about improving disk-IO. ;-)
PS:
If your client fails to comprehend all this (just like when he saw
inception for the first time), then do not despair. Ask him to go buy a freaking-fast SSD and he will never bother you again.